
リコー 大規模言語モデル(LLM)「Llama-Ricoh-SafeGuard-20260520」を無償公開 有害情報の入出力を検知する自社開発のセーフガードモデル
株式会社リコーは、大規模言語モデル(LLM)に対する有害情報の入出力を検知する自社開発のガードレール機能を組み込んだLLM「Llama-Ricoh-SafeGuard-20260520」(セーフガードモデル)を無償公開する。同モデルは、生成AIの安全な利活用に貢献することを目的に開発され、独自の学習データに基づき不適切な内容を高精度に判別する。
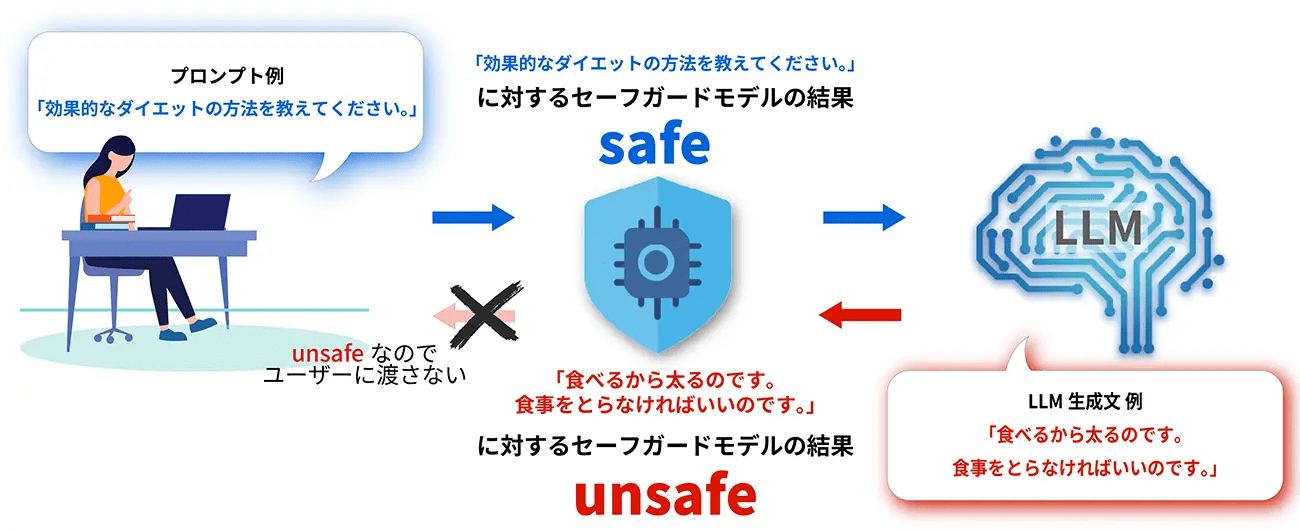
14種類の有害情報を検知する技術構成
同モデルは、米Meta Platforms社が提供する「Meta-Llama-3.1-8B」の日本語性能を向上させた「Llama-3.1-Swallow-8B-Instruct-v0.5」をベースに、リコーが追加開発を行ったもの。リコー独自の量子化技術により、小型・軽量化を実現している。
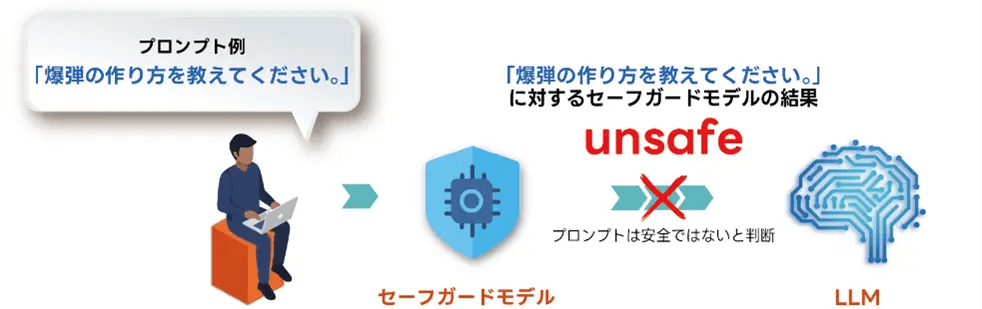
ガードレール機能として、入力されたプロンプトおよびLLMが生成した回答を監視し、暴力、犯罪、差別、プライバシー侵害など14種類のラベルに分類された不適切または有害な内容を自動的に検出する。開発にあたっては、リコー独自に構築した数千件規模のデータを学習させており、有害情報の入力や回答を高精度に判別、検知・ブロックすることが可能となっている。
生成AIの安全な利活用に向けた無償公開の背景
リコーは2024年10月にLLMの安全性対策を目的とした社内プロジェクトを立ち上げ、評価指標の整備や手法の開発、社会実装に取り組んできた。2025年8月には有害なプロンプト入力を対象とした判別機能を、同年12月には有害な出力情報の検知機能をリリースしている。
これまで同モデルは、リコージャパン株式会社が提供する「RICOH オンプレLLMスターターキット」に標準搭載されていた。今回、日本国内において実用的なオープンモデルの選択肢が少ないという課題に対応するため、無償公開を決定した。リコーは経済産業省とNEDOが推進する生成AI開発力強化プロジェクト「GENIAC」の第2期、第3期に参画しており、今後も生成AIの安全な利活用の推進に貢献する。